

반응형
이전글인 concurrent.futures 모듈로 병렬처리하기에서 빼먹은 웹 스크랩하는 방법입니다.
웹 크롤링은 검색엔진이 웹 사이트 찾아다니듯이 자동으로 여기저기 찾아다니는 것을 말하는데, 여기서는 단순히 웹 페이지 접속해서 해당 페이지 정보만 읽어오는 작업이라 웹 스크랩이라 표현했습니다.
네이버 증권 주소에 증권 코드를 담아 보내고 응답이 정상이면 해당 페이지 제목만 가져오는 간단한 스크랩 작업하는 예시입니다.
코드확인
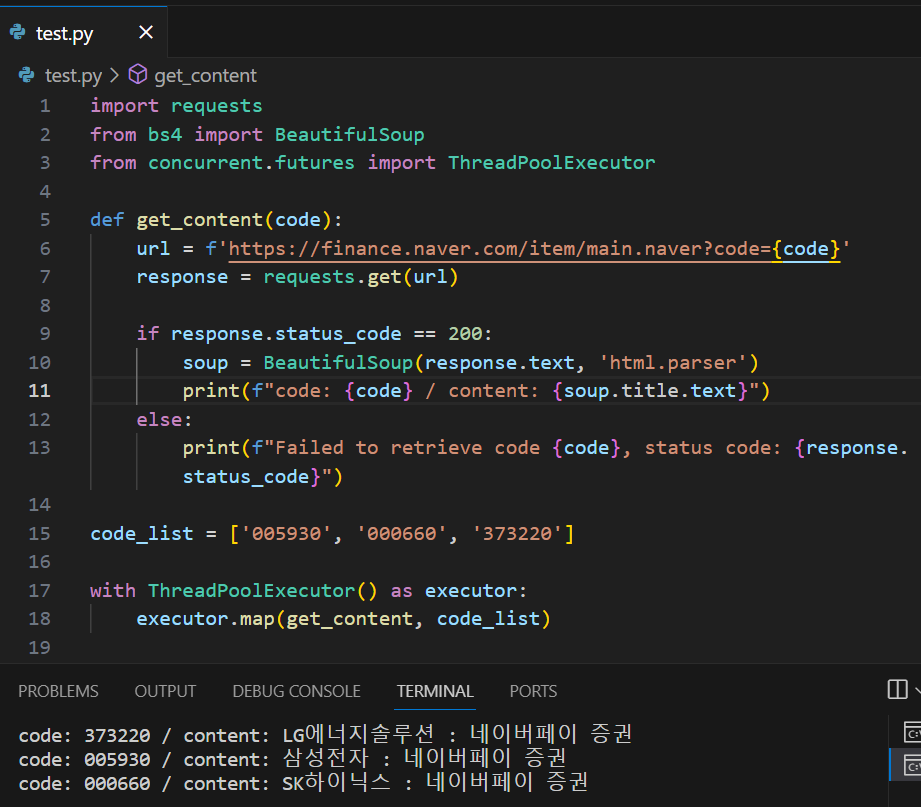
이전 포스팅과 구조는 동일한데
import concurrent.futures
를
from concurrent.futures import ThreadPoolExecutor
로 바꿔서 17번 라인을 좀 더 줄여서 썼습니다.
전체적인 흐름은
code_list에 증권 코드들을 리스트 타입으로 저장하고
ThreadPoolExecutor.map 함수로 code_list의 값을 하나씩 꺼내서 get_content를 실행하여
requests.get으로 url에 대한 응답을 받아서
response.status_code가 200이면 response를 beautifulsoup객체로 만들고
beautifulsoup객체에서 웹페이지 제목을 가져와서 print를 한 결과가 결과창에 출력되고 있습니다.
728x90
반응형